Light Link Solutions is a web development company providing IT and Digital Marketing services globally.
LightLink Solution
1006, The Spire Building, Sheetal Park, Puneet Nagar, Bajrang Wadi, Rajkot, Gujarat 360006

Optical Character recognition refers to computer vision problems that require hand-written or digital text images to be machine-readable. This technology eliminates the need to retype documents, money spent on storing them, and makes the data contained in the documents widely accessible.
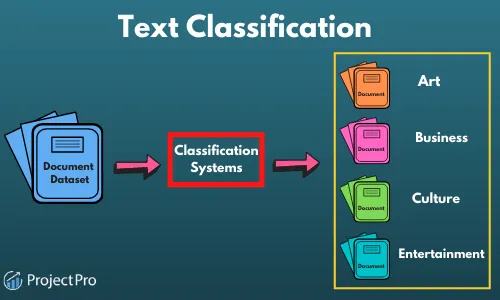
Text classification means assigning particular tags or categories depending on the content. This technology has a wide range of use like labeling topics, detecting spam, and the intent. By extracting important information from social media accounts, customer feedback, and many other sources it can provide valuable insights to your business.
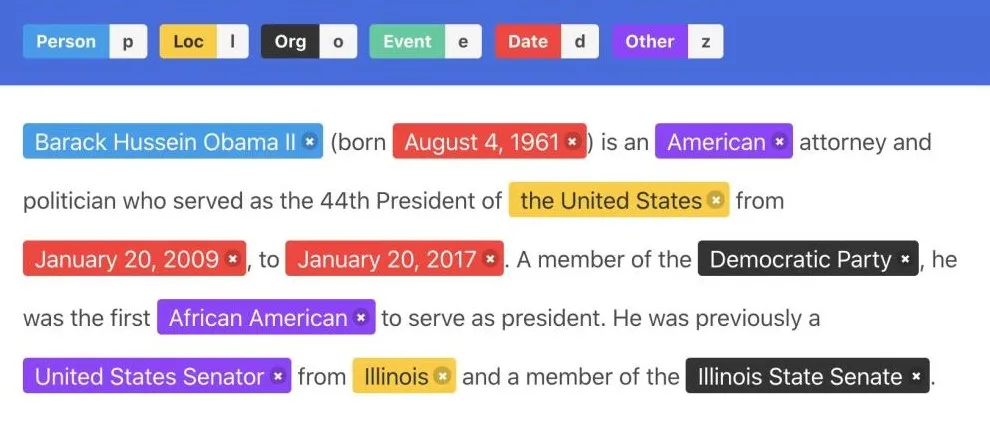
It is an information extraction process, the named entities are located and classified in the unstructured data. Then, these named entities are put into predefined categories. The category may include location, time, person names, organizations, quantities, etc. It is one of the vital entity detection techniques for natural language processing.

Sentiment analysis allows companies to understand how their customer base views their products. It can identify trend and nuances in large volume of text data including product reviews and social media post. The annotator labels the text as positive, negative or neutral for accurate analysis of a statement.
Hi! Click one of our representatives below to chat on WhatsApp or send us email to sales@lightlink.in
